
The completeness of the Gaia DR3 open cluster census
Star Clusters, Paper Summaries
21 October 2025 | Reading time: 4 minutes
Our galaxy — the Milky Way — is the only galaxy that we see from within. Having to study it from inside-out makes understanding our galaxy’s structure uniquely challenging compared to other galaxies. But that doesn’t mean that we should give up! Because everything in the Milky Way is so close to us, we can do much more in-depth studies with the content of our galaxy compared to others.
The best way to get around this difficulty is with tracers: some type of object that has easier to determine parameters than most other objects. Open clusters of stars, as groups of a few dozen to a few thousand stars, are one such tracer. They’re especially useful because their ages and distances can be determined much more accurately than individual stars.
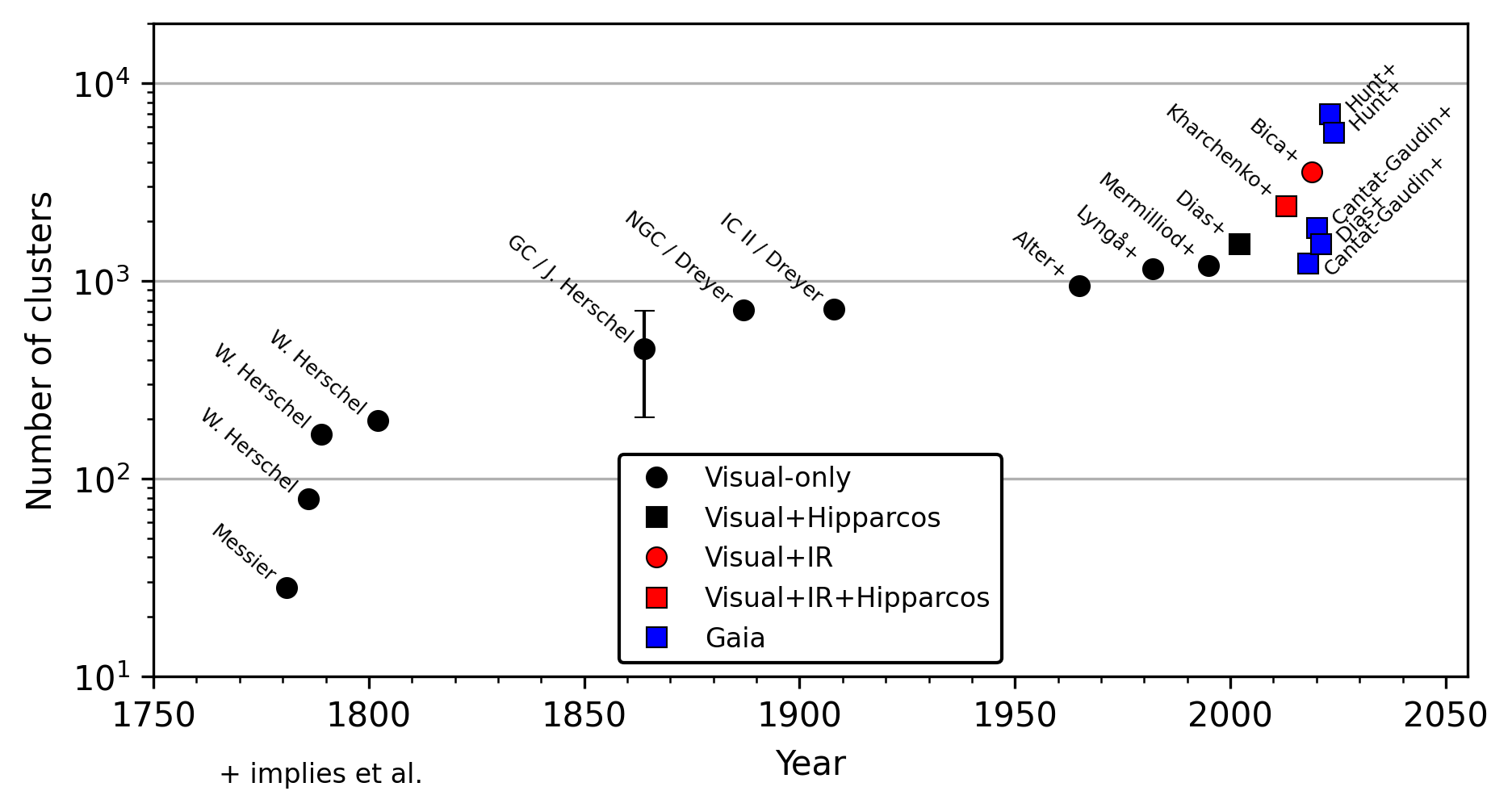
But one catch is that we’ve never really known how many open clusters are missing from our catalogues. Across the history of astronomy, large strides have been made in cataloguing clusters — especially in the era of Gaia (see below). But to use open clusters to trace larger elements of Galactic structure — like the density of clusters in a given area, or their age and mass distributions — we need a better understanding of what’s missing from these catalogues going forwards.
Setting up a model
In a pilot study, we developed and applied a method to do this on the Galactic anticentre. To do so, we simulated realistic clusters, and then tried to recover them using the pipeline that created my cluster catalogue. That lets us know which clusters can (or cannot) be recovered, depending on their parameters — like mass, distance, or age. That work was already published this year — so the only challenge left was to apply it to the full Gaia DR3 dataset.
After running about 80,000 injection and retrievals of simulated clusters, the next step was to fit a model to our simulations. But how can that be done easily, when simulated clusters have at least fifteen different parameters? I spent a lot of time finding the optimal model setup, and I managed to get it down to just three things: the number of stars in the cluster, the cluster’s relative density compared to Gaia data, and the significance threshold used to cut my catalogue.
Armed with this information, I played around with a few functional forms for a model — eventually settling on a logistic model of cluster detectability which, owing to how few variables it takes as input, makes it particularly simple to use, shown below for clusters of various densities (R tilda) by the dashed line, with the solid line with shaded uncertainty region showing the data that we fit to:
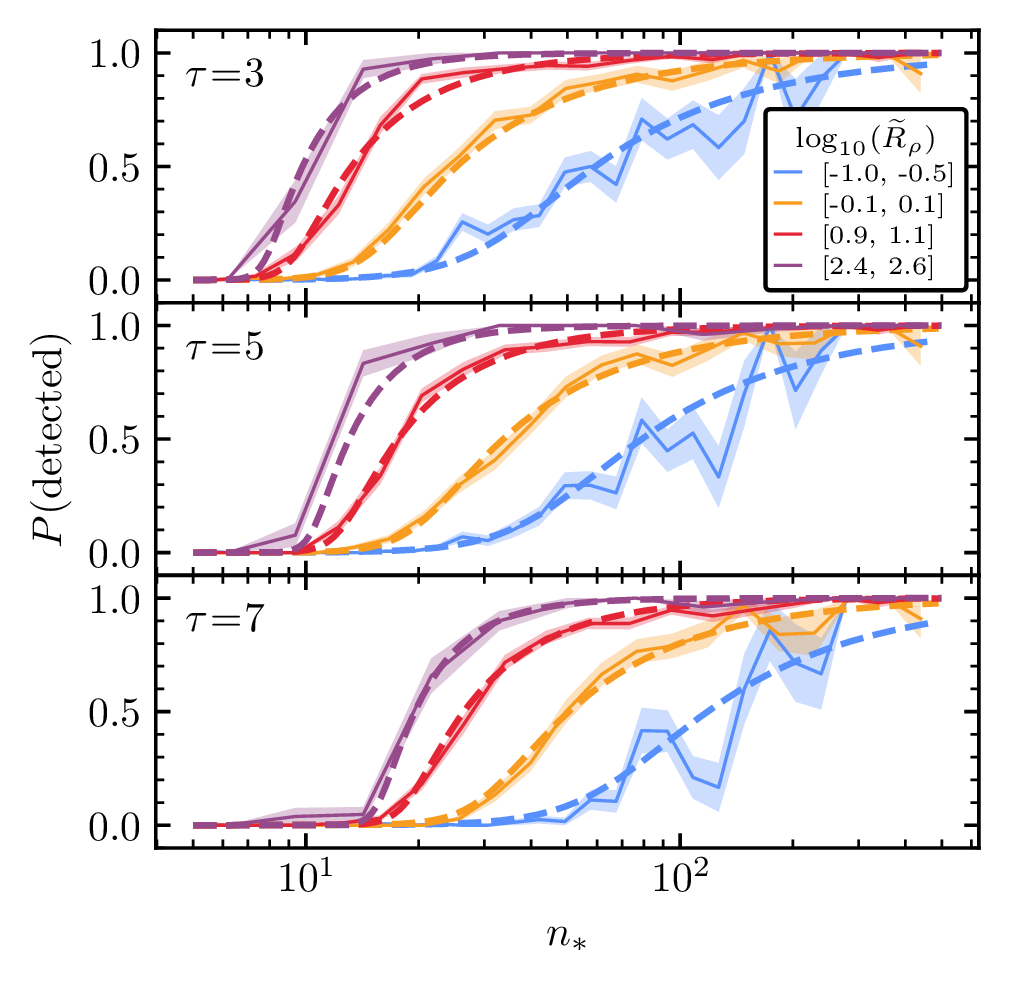
Best of all, our model is open-source, and is available right now as a pip installable Python package. We also published all of the data we used to fit the model, which could be used for other purposes — like estimating the completeness and purity of open cluster memberships in my catalogue. And, we also added the code used to simualte clusters to ocelot — so anyone else can have a go at using the code, too!
But why should I care about selection functions?
As a quick demonstration of why selection functions matter, we show one example in the paper: the detectability of an old, medium-sized cluster.
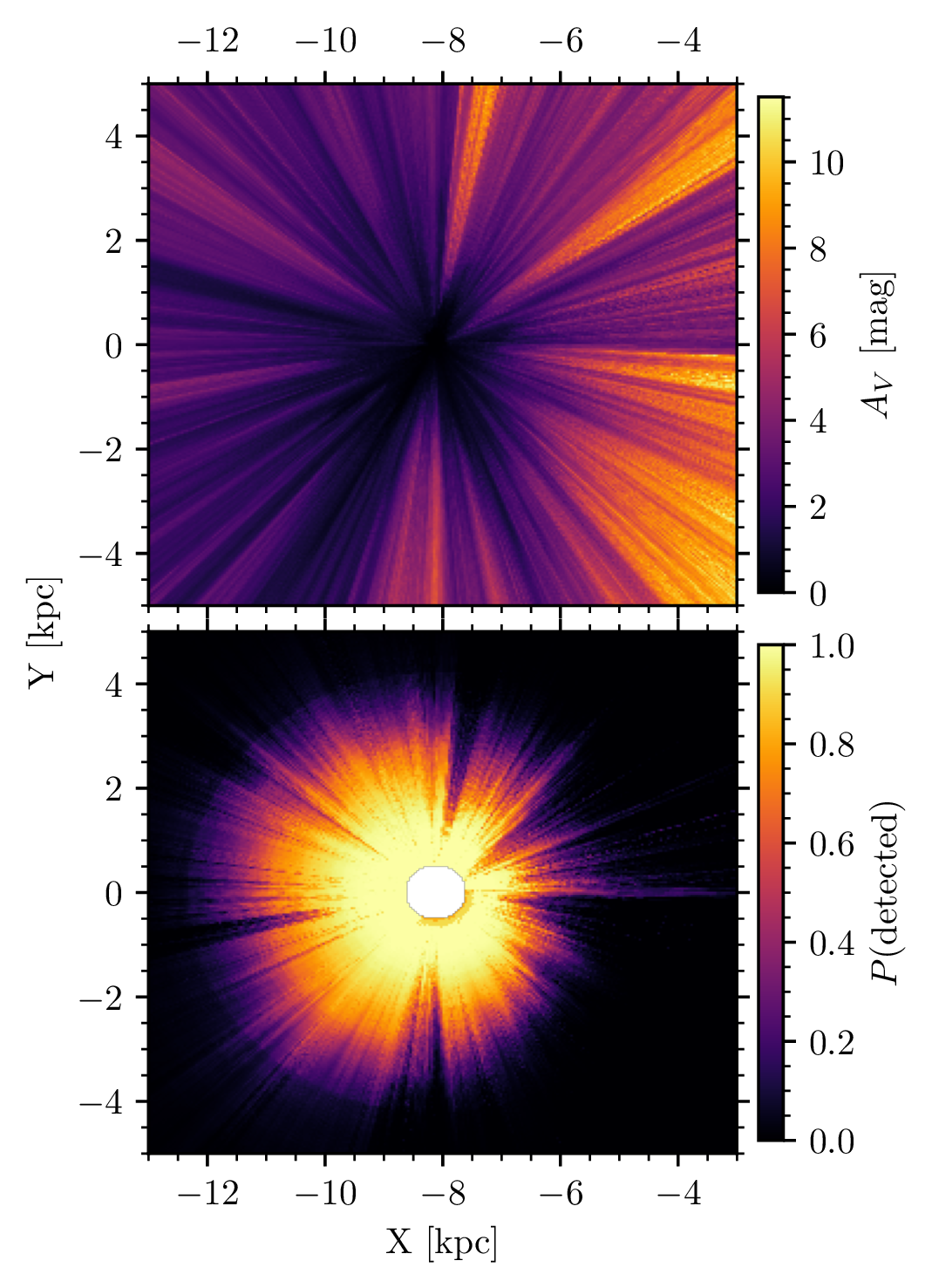
Our results can be used to make maps of the detection probability of any open cluster you can think of. Detectability often corresponds with other aspects of Galactic structure — like 3D dust extinction (shown above.) But where it can get particularly interesting is when making comparisons: for instance, are clusters on fast orbits easier to detect than clusters on circular ones?
The theory here is that clusters moving quickly will have fewer stars around them in the proper motion space used to detect them in Gaia data. This is exactly what we see, and it gets particularly complicated: depending on which direction it’s going ‘faster’ in, you’ll see different regions have different areas of ‘boosted’ detection probability.
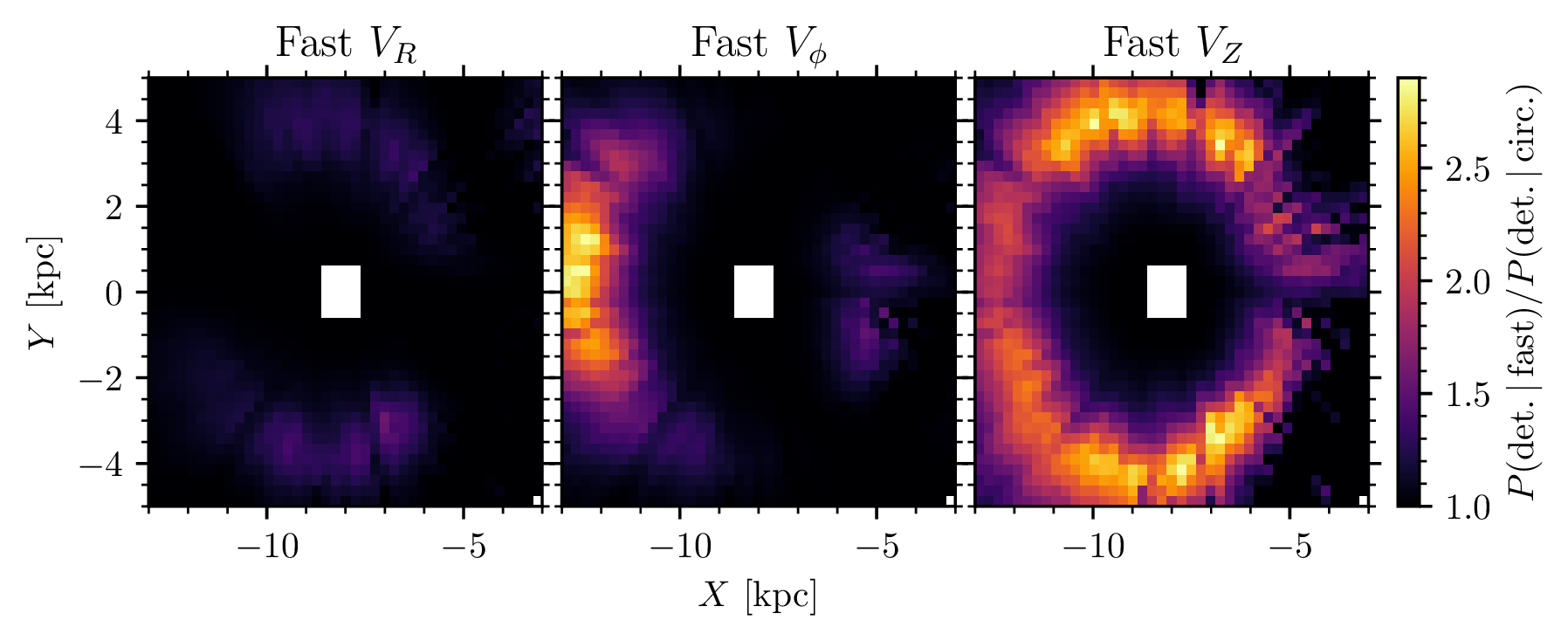
We can already say here that previous papers that have analysed things like the velocity distribution of the Milky Way (but without selection functions) will have been biased: their sample will have contained more fast-moving clusters than slow-moving ones, due to this selection effect. What’s happening is that in cases where the boost to orbital speed is fully projected into a proper motion axis observed by Gaia, the detection probability boost is highest. Radial velocities aren’t used to detect open clusters by my catalogue, so only a high tangential motion (i.e. proper motion) boosts detectability.
All of this (and more!) is now available to read about on the arXiv in our new paper, which has been submitted to A&A. You can also check out the accompanying Python package.