Which clustering algorithm is the best at retrieving open clusters in Gaia data?
Star Clusters, Machine Learning, Paper Summaries
16 February 2021 | Reading time: 9 minutes
Over a dozen papers have reported new discoveries of open clusters in Gaia data at the time of writing, in less than three years since the release of Gaia DR2. At the core of all papers in this field are clustering algorithms. Gaia data contains over 1 billion stars – far too much to accurately search through by hand, like astronomers once did before the 21st century. The many different algorithms that have been tried for this task have never been compared before in an astronomy context – meaning that we simply don’t know how their reliabilities, sensitivities and speeds compare. So: that’s what we tried to answer!
In my first ever published paper out now in Astronomy & Astrophysics, I worked with my supervisor Sabine Reffert on laying the groundwork for the rest of my PhD. We compared a lineup of three different algorithms, and actually found that a method that hasn’t been used for open clusters before (HDBSCAN) is better than the existing literature approaches. However, it also required a lot of development to adapt it for astronomy – especially to reduce its false positive rate.
In this blog post, I’m going to give a more informal overview of the paper.
The algorithms
I looked into a lot of different algorithms for us to try and comapre. Since a lot of them are quite similar, we narrowed it down to just three: DBSCAN, HDBSCAN and Gaussian mixture models. I’ll briefly summarise them below.
DBSCAN is probably the most successful algorithm that has been used on Gaia data so far for finding new open clusters. For instance, Castro-Ginard et al. (2020) found 582 new objects in Gaia DR2. It’s pretty straightforward: you set two global parameters that act a bit like a density threshold. Any clusters in your data denser than this threshold will be returned. The hardest part is setting a global threshold that works everywhere, and so we tried two methods for this – a method developed by Castro-Ginard et al. and one I made myself.
HDBSCAN is a natural evolution of DBSCAN released in the past few years, almost 20 years after DBSCAN. It works in a similar way except the user only needs to set a minimum cluster size. Not only does it automatically determine other things to set a density threshold accurately for you, it also does this on local levels, meaning that clusters can be returned in different areas of a dataset with different density levels (unlike DBSCAN, which you’d have to run multiple times.) In theory, it should be more sensitive than DBSCAN because of this. HDBSCAN has never been used to specifically recover open clusters in Gaia data, although Kounkel et al. (2019, 2020) used it in studies of galactic moving groups and populations.
Finally, Gaussian mixture models are a method that has been used for decades to retrieve open clusters from a variety of datasets. Cantat-Gaudin et al. (2019) found 41 new open clusters with a Gaussian mixture model approach. It’s also a closely related algorithm to K-Means, the core clustering component of the membership assignment code UPMASK used by Cantat-Gaudin et al. (2018)‘s ubiquitous catalogue of open clusters in Gaia DR2. It works entirely differently to the other two options: the dataset is separated into Gaussian components in an iterative approach, and components that look compact enough to be open clusters are selected for further study.
The data
Next up, we needed some clusters to compare the algorithms on! We chose to use real Gaia data (instead of simulated data) so that we could also see how the algorithms and our pipeline could deal with real-world issues like systematics.
I selected 100 open clusters from the MWSC catalogue (Kharchenko et al., 2013) to use as our main list of clusters. Since this is a pre-Gaia catalogue, quite a lot of the objects it lists shouldn’t actually be real – at least ~55 of these objects don’t seem to be visible in Gaia at all. But this is ok – it means we can see how good the algorithms are at discriminating between real and false open clusters.
These 100 fields contained 1385 open clusters in total which I was able to crossmatch against after trying to find the 100. This meant that we could also compare to an extra list of objects (albeit without as much human supervision), seeing how the sensitivity of the algorithms was affected by things like cluster distance and size.
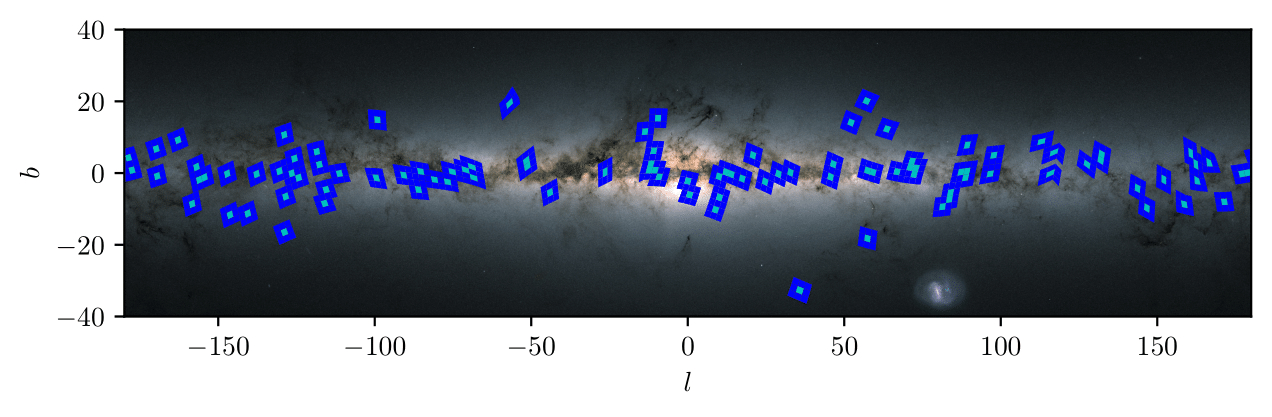
Figure: The 100 fields and their locations on the galactic disk. They’re randomly distributed which gives us a really nice sample of diferent galactic environments. They’re also allowed to overlap, as only the central HEALPix pixel out of the nine per field reliably has no edge effects. (The odd shapes of some fields are due to this plot being in galactic co-ordinates whereas the fields are defined in ra/dec.
Processing the results
Running the algorithms alone was not enough. HDBSCAN in particular was quite the rascal, reporting tens of thousands of false positives that aren’t real open clusters. So, we needed a way to cut through the noise and eliminate a large amount of false positives with other knowledge and methods.
In addition to using a cut on parameters proposed by Cantat-Gaudin et al. (2020), I also developed a significance test (that acts a bit like a “signal to noise ratio” for open clusters in Gaia data). By comparing the nearest neighbour distances between stars within a cluster and field stars surrounding a cluster, the test evaluates whether or not the cluster’s nearest neighbour distribution is incompatible with being drawn from the field’s nearest neighbour distribution. If so, then that suggests that a real overdensity has been found!
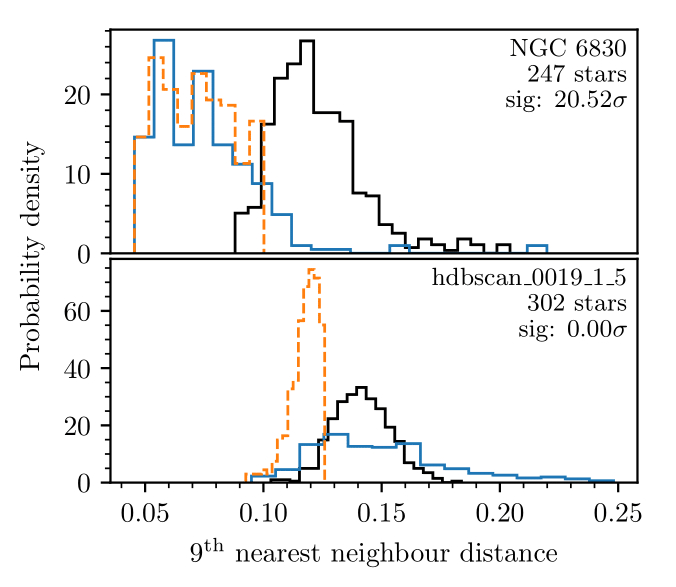
Figure: The distributions the cluster significance test is based on. In the first plot, the nearest neighbour distribution of stars in NGC 6830 is shown in blue – it’s clearly very different to the field stars (shown in black) and has a significance of 20.52 sigma (very high.) On the bottom is a HDBSCAN false positive with 0 sigmas of significance, since the cluster distribution is compatible with being drawn from the field star distribution.
Finally, I crossmatched to a few other catalogues to see how many objects were found. The crossmatching also accounted for systematics in the source catalogues as well as in Gaia and source data, trying to reduce the number of missed crossmatches as much as possible.
Which algorithm is best?
The results painted an interesting picture! Firstly, the main list of 100 clusters revealed the primary differences between the algorithms. DBSCAN (with the Castro-Ginard et al. parameter method) was relatively sensitive, finding just over half of the believed-to-be-real 100 clusters and without a single false positive. My own parameter method increased the number of clusters detected by around 10%, but at a price since a handful of false positives were then introduced. HDBSCAN was the most sensitive of the three, finding 82% of true positive clusters – but while also having the highest false positive rate, with 1 in 5 of its clusters not being real. Finally, Gaussian mixture models had the worst sensitivity (only detecting the largest 33% of clusters) but without any false positives as with DBSCAN.
A major constraint on the algorithm’s usefulness is their speed. DBSCAN only took around 10 hours to run on the entire sample of fields, with HDBSCAN taking just over one day but Gaussian mixture models taking around 8 days. In practice, DBSCAN and HDBSCAN have runtimes that scale as O(n log n) whereas Gaussian mixture models scale as O(n2), making them prohibitively slower for larger and larger fields. For any problem larger than this one (and future Gaia releases will have more usable data!), Gaussian mixtures could be extremely computationally intensive to apply.
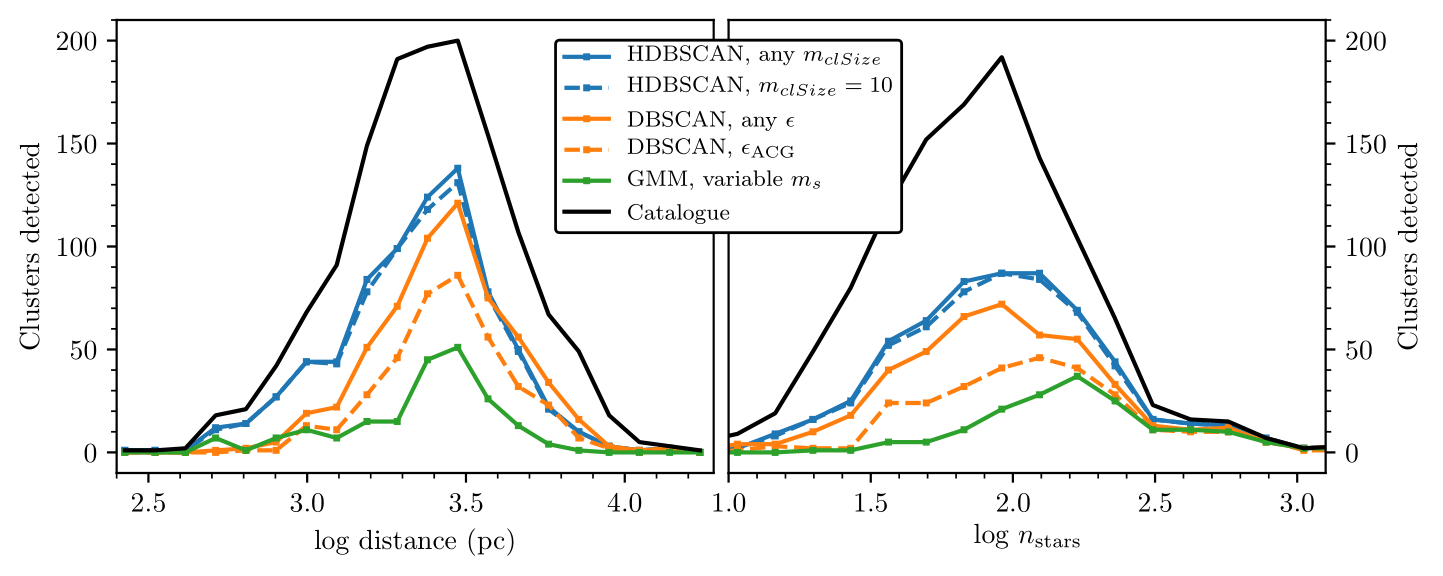
There were also the remaining 1285 clusters in all of the fields, and putting them plus the 100 main ones together painted an interesting picture of the positive detection rate of the algorithms as a function of distance and size:
Figure: The distance and size dependence of detected clusters for all algorithms. HDBSCAN is noticeably better at close distances, with Gaussian mixture models only detecting the largest clusters.
HDBSCAN’s locally-adaptive cluster detection performed best over almost all distances – especially nearby (within ~2 kpc), where open clusters have a larger size on the sky and are locally sparser, but stand out well in proper motion and parallax. DBSCAN’s global parameter can only be optimised for one part of a dataset (typically for more distant clusters), causing it to perform poorly without cutting the data in some other way and doing repeat runs. Gaussian mixture models were mediocre as a function of distance but did ok at some of the very nearest objects.
A final point to add is on membership lists. It’s not just about detecting a cluster, but also about detecting all member stars of a cluster! Overselecting the cluster in Gaia data causes its colour-magnitude diagram to be highly contaminated, while underselection reduces its significance within Gaia data and misses the true extent of the cluster. Here, HDBSCAN and Gaussian mixture models really shone through, with DBSCAN lacking. Gaussian mixture models’ iterative approach meant that clusters were always well fit; equally, HDBSCAN’s local-adaptivity had similar results, with both algorithms (when they both detected an object) producing consistent membership lists that appear clean and correct. However, DBSCAN’s single global parameter per-field is often not optimal for all objects within that field equally, frequently under or over-selecting members of the cluster or even splitting it into multiple components.
New objects!
Finally, we were encouraged by the reviewer to investigate whether or not we found any new objects in our results. I scoured the HDBSCAN results for any candidate new objects with good quality colour magnitude diagrams and was able to find 34 new objects! 41 are in the paper, although it later turned out ~7 are probably reported in existing papers that I missed – including five that went on the arXiv the day before I resubmitted the paper… argh!
Regardless, it goes to show that more work needs to be done to extract all open clusters hiding in Gaia data – and a new methodology should be very helpful to achieve this!
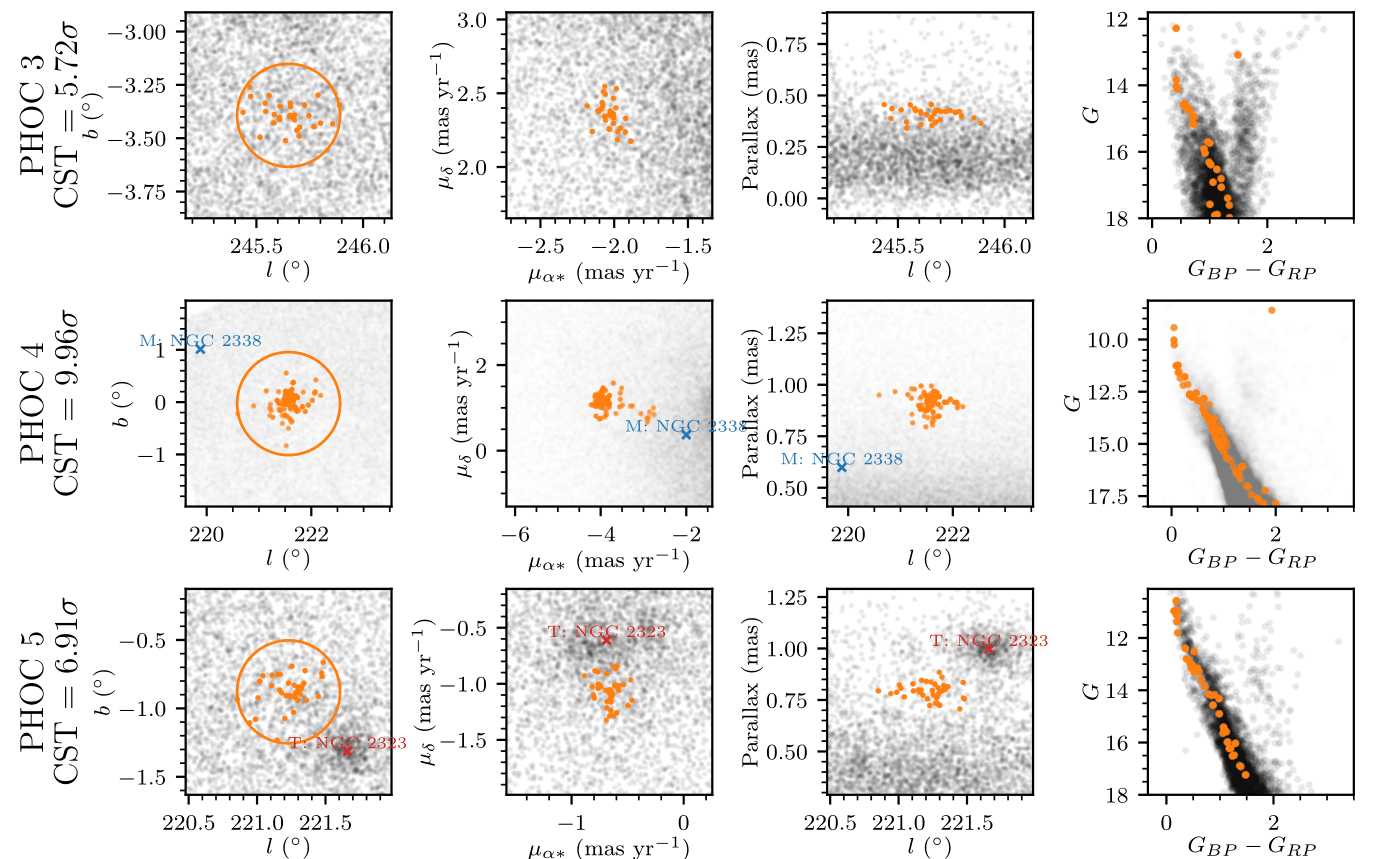
Figure: Some of the candidate new objects! Nearby literature clusters are plotted too.
Conclusion
In this work, we compared three algorithms for detecting open clusters in Gaia data – the first ever side-by-side comparison of these algorithms in an astronomy context. We found that a new method for detecting open clusters, using HDBSCAN plus our additional developed postprocessing steps, seems to be the best in terms of sensitivity, speed and member recovery! However, care must be taken in postprocessing steps to remove the large numbers of false positives it produces. Existing methods based on DBSCAN and Gaussian mixture models are unlikely to have found all new objects available in Gaia.
In the future, it will be exciting to run our new HDBSCAN methodology on new Gaia data releases (EDR3 is now out!). Who knows what we might find. We will probably also develop a machine learning classifier similar to the one that Castro-Ginard et al. used to automate the process of classifying open cluster colour magnitude diagrams based on their quality.
Want more? You can check out the full paper here.